In this post, I’ll present a model I am currently working on during the course of my Bachelor’s thesis. In this post, a model to select the top answer for a question in community question answering forums is presented. The model here is largely inspired from “Improved Representation Learning for Question Answer Matching.” – Tan, Ming, et al. and “Teaching machines to read and comprehend.”-Hermann, Karl Moritz, et al.
Neural networks have consistently performed well on tasks which depend upon semantic information for optimum results. The presented model in this post comprises of Long Short Term Memory (LSTM) networks, which have been very famous in the past few years since the inception of sequence modeling using neural networks. LSTM were first proposed in 1997, though their practically powerful influence was only recognized recently with the improvement in processing capabilities, and the rise in use of GPU’s for running deep learning models.
Long Short Term Memory networks
Inspired by the way humans read and understand text, Recurrent Neural Networks (RNN) have a solution to resolve these dependencies of current information that go in the past. At any time state, the output is dependent on the current input as well as information of the previous inputs.There are variants of RNN like Long Short Term Memory (LSTM) and Gated Recurrent Units (GRU) that solve some of the problems of RNN like gradient vanishing and remembering longer sequences. This type of modeling has shown very good results on language modeling tasks.
An LSTM cell comprises of 3 gates to remember a part of inputs in the previous time steps.

Input Gate
The input gate layer in the first equation below is a sigmoid layer to decide which values in the cell state would be updated. This results in 
![i_t = \sigma( W_i . [h_{t-1} , x_t] + b_i )](https://s0.wp.com/latex.php?latex=i_t+%3D+%5Csigma%28+W_i+.+%5Bh_%7Bt-1%7D+%2C+x_t%5D+%2B+b_i+%29&bg=fffdfd&fg=606666&s=0&c=20201002)
![\widetilde{C_t} = tanh( W_c . [h_{t-1} , x_t] + b_c )](https://s0.wp.com/latex.php?latex=%5Cwidetilde%7BC_t%7D+%3D+tanh%28+W_c+.+%5Bh_%7Bt-1%7D+%2C+x_t%5D+%2B+b_c+%29&bg=fffdfd&fg=606666&s=0&c=20201002)
Then, in the equation above, we create a candidate new cell state content to be updated into the final cell state for the current time step.
Forget Gate
The forget gate has the function of deciding which information in the cell memory to keep, and which to forget.
![f_t = \sigma( W_f . [h_{t-1} , x_t] + b_f )](https://s0.wp.com/latex.php?latex=f_t+%3D+%5Csigma%28+W_f+.+%5Bh_%7Bt-1%7D+%2C+x_t%5D+%2B+b_f+%29&bg=fffdfd&fg=606666&s=0&c=20201002)
It looks at 


In the above equation, we update the cell contents to new contents. Here, the forget gate 

Output Gate
The output gate layer decides the output at each time step. The output of the LSTM cell uses a sigmoid layer on inputs 

![o_t = \sigma( W_o . [h_{t-1} , x_t] + b_o )](https://s0.wp.com/latex.php?latex=o_t+%3D+%5Csigma%28+W_o+.+%5Bh_%7Bt-1%7D+%2C+x_t%5D+%2B+b_o+%29&bg=fffdfd&fg=606666&s=0&c=20201002)

This structure of an LSTM helps it model the dependencies of previous inputs efficiently.
Model Architecture – Components
Our proposed model for question answering task uses a variant of LSTM’s as discussed in the last section, as well as some mechanisms such as attention. Lets discuss about them in the following parts.
Bi-directional LSTM
Bi-directional LSTM’s were introduced in 1997 by Schuster and Paliwal. They are different from LSTM in the way that they model input in both directions, from beginning to end as well as from end to the beginning. Using such a structure, the outputs can resolve dependencies on the future and past informations. They have proved to improve results in a variety of tasks as compared to vanilla LSTM’s. They perform especially better on tasks where the context information is very important.
Attention
Attention mechanisms are a recent trend in deep learning. This mechanism is loosely related to the visual attention phenomenon experienced by humans. Attention has been very common in the Computer Vision domain, and recently has found applications in the Natural Language Processing (NLP) domain.
Structurally, in neural networks, attention is used to revisit the input to decode the current output. In Computer Vision, attention is popularly used in CNN’s for a variety of tasks such as image classification, visual question answering, image captioning, etc. In NLP, some information that models such as RNN and LSTM are not able to store because of various reasons, can be reused for better output generation (decoding). Attention has showed specially good results in machine translation, while showing better results in other tasks as well.
In our task, attention shall be used to construct the answer vector. When the LSTM gives it’s output for an answer sentence, at each time step for every word, attention on the whole question will scale the answer word vectors according to their importance. This will result in varying the importance of each answer word based on it’s respective question.
A short-coming of attention is that it increases the number of parameters in the model. This increase of parameters now needs more data to generalize to the task at hand, as compared to models without attention.
The proposed Model
The proposed model is shown in the following figure. As discussed above, the model uses Bi-directional LSTM to vectorize sentences. The input at each time step to the model is Glove 50-dimensional word embedding. The input sentences i.e. question and candidate answer posts are served as input to the model using these word embeddings.
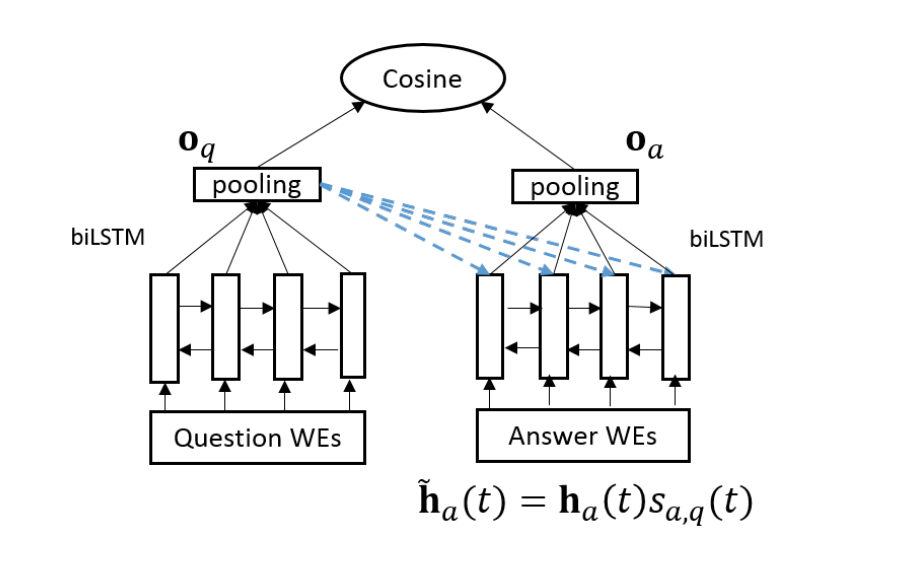
At each time step, the bi-directional LSTM gives 2 outputs – one from the forward moving LSTM cell and another from the backward moving LSTM cell. For the model proposed here, we concatenate the two vector outputs at each time step. For each output 




In the above equations, 

After obtaining the vectors for question and answer, we use cosine similarity measure to obtain the a value for a question answer pair. For training the model, cosine hinge loss function is used as shown below,

In the above equation, 


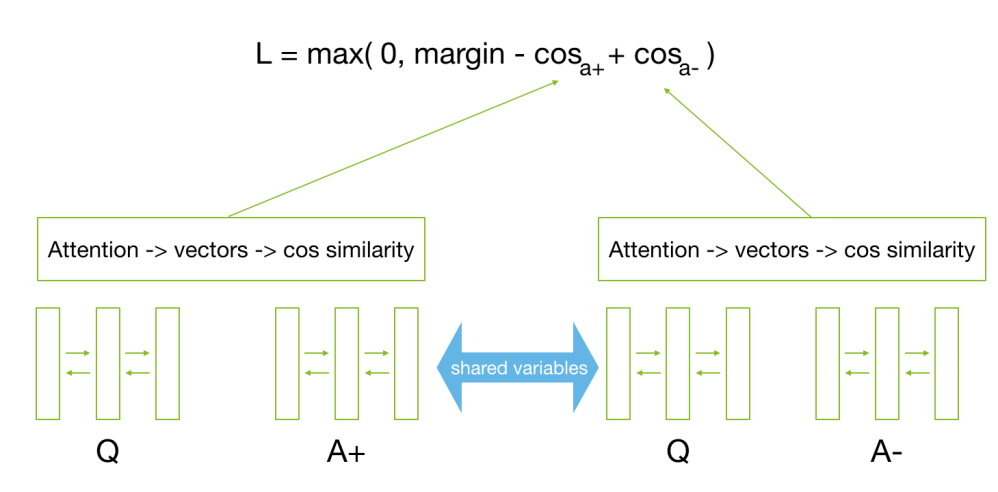
For training the proposed model, we have used WikiQA dataset. The dataset has a total of 3047 questions with candidate answers. The source of this dataset is Bing query logs from the years 2010-11. For each question, our model forms a pair of wrong answer and correct answer to train the model. WikiQA has a variety of questions from no fixed domain, where each question has many candidate answers like the community question answering domain, thats why we chose this dataset. The questions in WikiQA have no particular domain, hence the proposed model learns the general features that ranks an answer for each question, which can later be transferred on our required domain of MOOC discussion fora.
Model Parameters and Training
The proposed model uses Glove embeddings for the words in the input sentence. The word embeddings are input to the bi-directional LSTM at each time step. The cell memory size of the bi-directional LSTM was kept at 128 with a dropout output probability of 0.5. The margin for the loss function was set at 0.3. The batch size for training was 16 at each training step, and the model was trained using Adam Optimizer with a learning rate of 0.0001.
Using the above parameters, the model was trained on the WikiQA dataset giving very close results to the models proposed in 2016. In the year 2017, this model performs 2-3% points lower to the state-of-the-art.
You can find the github code for this post here. The model is coded on TensorFlow v1.3. Please let me know if you have any questions or suggestions regarding the material presented in this post.
